Image resolution that we use for training: 580x180
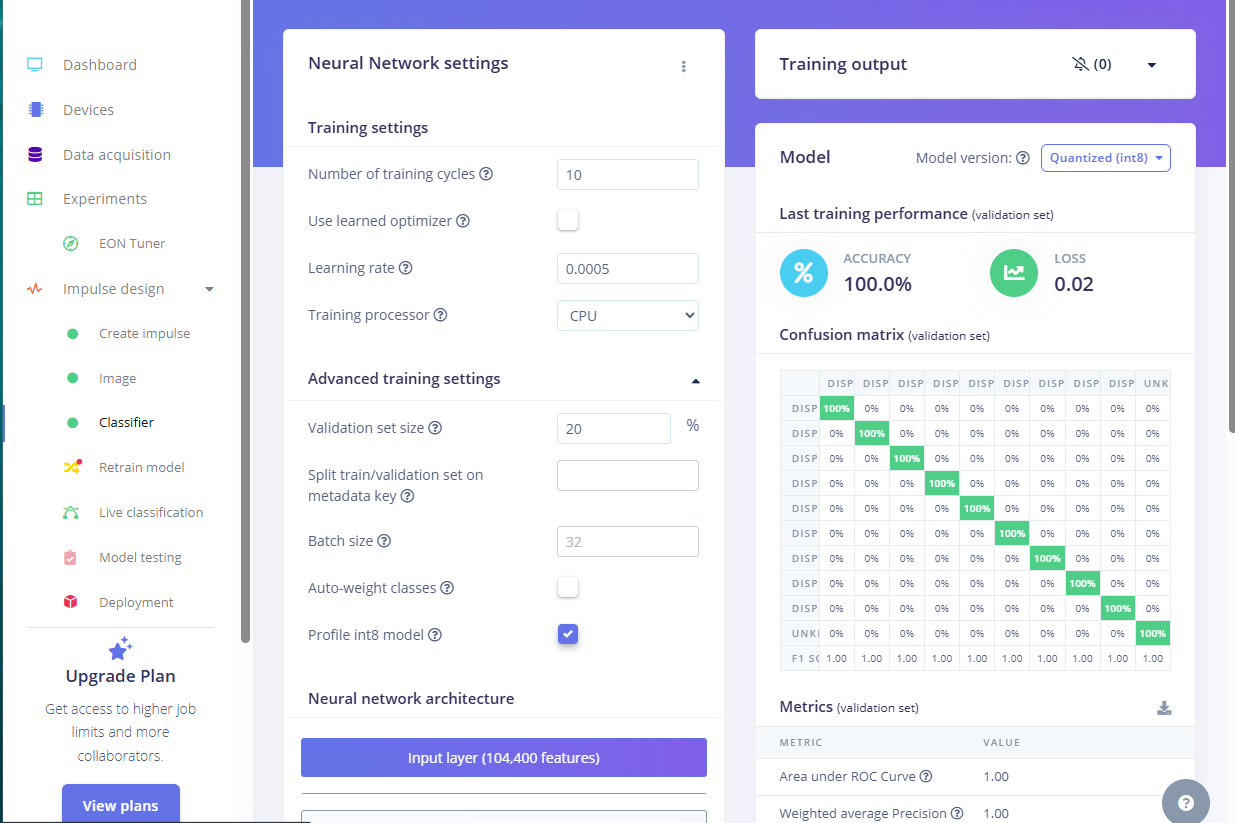
The output is 2MB Quantized model and 8MB unoptimized model.
We notice that when using Quanitzed 8 bit model, we are having some issues and the camera is not able to reliably detect the object when there are slight environment changes, such as a few dust particles land on the Display or it may even detect a 100% match when the dispaly segment is defective.
We thought that we could improve this by using the Unoptimized model but we have this issue (Failed to allocate tensors)
Hi, this means the model cannot fit into RAM. How are you loading the model? With load_to_fb=True or without that? If without that, then it’s ending up in the heap versus the frame buffer, which uses most of the available RAM for just storing the model and not the tensor arena. Otherwise, it’s because your model is using up more RAM than is available actively.
import sensor
import time
import ml
# Configure sensor
sensor.reset() # Reset and initialize the sensor.
sensor.set_pixformat(sensor.GRAYSCALE) # Set pixel format to RGB565 (or GRAYSCALE)
sensor.set_framesize(sensor.HD) # Set frame size
#sensor.set_windowing((500, 300, 840, 240)) # For FullHD
sensor.set_windowing((330, 190, 580, 180)) # For HD
#sensor.set_windowing((200, 190, 380, 380)) # For SVGA
#sensor.set_windowing((190, 100, 320, 160)) # For WVGA
sensor.set_auto_exposure(True)
sensor.set_contrast(3)
sensor.skip_frames(time=2000) # Wait for settings take effect.
model = ml.Model("trained.lite", load_to_fb=True)
labels = [line.rstrip("\n") for line in open("labels.txt")]
clock = time.clock()
while True:
clock.tick()
img = sensor.snapshot()
print("**********\nTop 5 Detections")
# This combines the labels and confidence values into a list of tuples
# and then sorts that list by the confidence values.
sorted_list = sorted(
zip(labels, model.predict([img])[0].flatten().tolist()), key=lambda x: x[1], reverse=True
)
for i in range(5):
print("%s = %f" % (sorted_list[i][0], sorted_list[i][1]))
I can run my model quanitzed without any issues.
I have a few more questions:
Does my HW support unoptimized (32 bit float) models?
The edge impulse suggests the following:
The hardware does support float32, however, you are running out of RAM. You need to make the model smaller. Otherwise, you are welcome to modifying the heap/fb_alloc stack sizes in the firmware given the two variables I mention to increase the heap. Note that you will have to take RAM from other buffers to increase the heap size.