I’m just going to list down my entire workflow thus far, and perhaps you could tell me where I’m going wrong. I apologize in advance for making yall read through this lengthy post, I was hoping to bring everyone up to speed with what I’ve got so far.
Using this projection model, world coordinates are translated to camera coordinates using the extrinsic matrix for translation and rotation (Mext), then the projection matrix projects the point from camera coordinates to film/image coordinates (Mproj), then its scaled to pixel coordinates using an affine transform (Maff).

Using this model, the extrinsic model is easy to understand - its just a 4x3 where the upper left 3x3 is the rotation matrix, the last 3 rows of the last column is the translation vector and the bottom right is a 1 (for homogeneous coordinates I presume):
Image 2

The projection matrix is derived from rules of similar triangles as such:
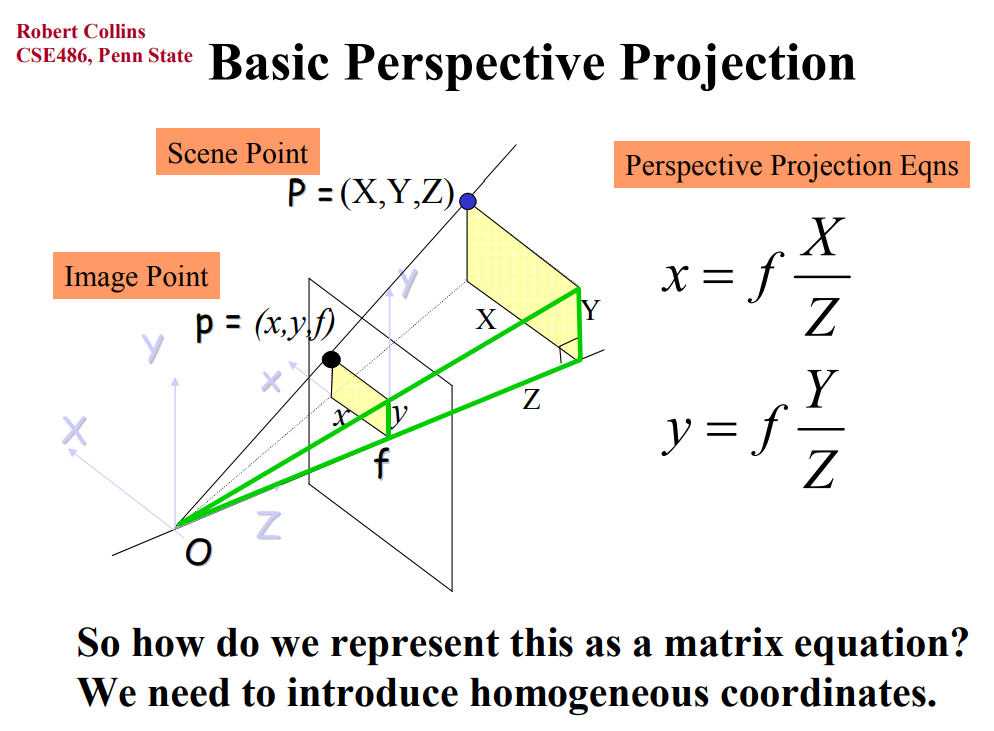
This system of equations can then be rewritten in matrix form using homogenous coordinates (keep in mind the division by Z comes from converting homogenous coordinates back to cartesian):
Image 4

The full matrix then becomes:

However as the points lie coplanar on z = 0, the third column of the extrinsic matrix can be eliminated. And since the last row of the projection matrix is 0, the last row of the extrinsic matrix can be eliminated:
Image 6

This then produces a homography matrix, relating the 2 planes together such that (pixel space) = H * (world space):
Image 7

In order to find the values of [h11, …, h13], there are 9 unknowns and each set of correspondence only provides 2 constraints, so with 4 points we only have 8 constraints (shown later). From my understanding, there is 2 ways to set the final constraint; either set h33 to 1, or impose the unit vector constraint on h such that it does not provide the trivial solution of h = 0.
Image 8

However, if h33 is actually 0, the first method does not work, hence the focus shall be on the second method. Multiplying out the homography matrix (expanding matrix multiplication from image 7, last row), we get the set of linear equations:
Image 9

Which can be represented in matrix form as:
Image 10

This can then be solved using SVD (singular value decomposition):
Image 11

Usually in numpy, the column of U (or known as Vt in other literatures) associated with the smallest eigenvalue in D would be the last column (index -1). Reshaping this column of 9 into a (3, 3) matrix then provides the homography matrix.
As we’ve established earlier, the conversion of world points to pixel coordinates involves multiplying the affine matrix, the projection matrix, and the extrinsic matrix. Typically, the intrinsic matrix K is considered to be a combination of the affine and projection matrix (hence the division of pixel size below). The following code is code I’ve written based off my understanding thus far.
def getCameraIntrinsicMatrix(focalLength, pixelSize, cx, cy): #parameters assumed to be passed in SI units (meters, pixels wherever applicable)
fx = fy = focalLength / pixelSize #focal length in pixels assuming square pixels (fx = fy)
intrinsicMatrix = np.array([[fx, 0, cx],
[0, fy, cy],
[0, 0, 1]])
return intrinsicMatrix
given the focal length (typically mm - convert to m first), pixel size (typically um - convert to m first, and assumed to be square), the center of the image in pixels, the intrinsic matrix is then calculated as shown above.
We need to calculate the homography matrix as well (I’m assuming svd will be implemented in ulab by the time I figure out the rest of this).
def estimateHomography(pixelSpacePoints, worldSpacePoints):
A = np.zeros((4 * 2, 9))
for i in range(4): #construct matrix A as per system of linear equations
X, Y = worldSpacePoints[i][:2] #only take first 2 values in case Z value was provided
x, y = pixelSpacePoints[i]
A[2 * i] = [X, Y, 1, 0, 0, 0, -x * X, -x * Y, -x]
A[2 * i + 1] = [0, 0, 0, X, Y, 1, -y * X, -y * Y, -y]
U, S, Vt = np.linalg.svd(A)
H = Vt[-1, :].reshape(3, 3)
#verifying u = H*X - comment out if not required
for pixelPoint, worldPoint in zip(pixelSpacePoints, worldSpacePoints):
homogeneousWorldCoords = np.array(list(worldPoint) + [1])
pixelHomogenous = np.matmul(H, homogeneousWorldCoords)
pixel = list(map(lambda x: round(x), pixelHomogenous / pixelHomogenous[-1]))
print("H * X =", pixel[:2], " original pixel point:", pixelPoint)
return H
I’ve verified that multiplying the world points with the homography matrix does indeed return the original pixel values corresponding to that 3D world point.
Now comes the part I’m stuck on - I’ve successfully obtained the homography matrix, I have my camera’s intrinsic matrix, and we’ve established that pixelPoints = H* worldPoints, and H = K * extrinsicMatrix (refer to image 7, middle row) so I assume that by multiplying K^-1 (inverse of K) with H, I should be able to obtain the extrinsic matrix.
def obtainPose(K, H):
invK = np.linalg.inv(K)
Hn = invK @ H #normalized by K
R1 = Hn[:, 0] / np.linalg.norm(Hn[:, 0]) #first column of rotation matrix
R2 = Hn[:, 1] / np.linalg.norm(Hn[:, 1]) #second column of rotation matrix
R3 = np.cross(R1, R2) #third column of rotation matrix
R = np.zeros((3, 3))
R[:, 0] = R1
R[:, 1] = R2
R[:, 2] = R3
t = Hn[:, -1] #translation vector
return R, t
The problem is that the translation vector is in the scale of millimeters, when I know for a fact the camera was placed at least tens of centimeters away.
If I’ve gone wrong anywhere please let me know, and if there is a loss of scale somewhere, I’m not sure where it is. Perhaps is it due to homogenous coordinates not being affected by scale due to division of the last element.